时间轮算法
场景
如:我们在RPC框架中每个请求肯定都会有超时的设计,那么我们怎么去设计这个超时的机制呢?都会说我们设置定时任务呀,定时多久执行一次,判断请求是否超时,思路可以,但是具体我们怎么实现呢?
方案1:
我们做一个定时任务1S遍历一次请求列表,查看多个请求哪个请求超时了就从列表中删除,当然,这是一种解决方案。 我们来看一下上面这种思路,如果有10个请求的超时时间是1S、5S、10S….30S,我们每次遍历都需要把每个请求都处理一遍才能找到超时的那个任务,那么中间是不是就出现了很多无意义的操作呢? 有什么更高效的方法吗?
方案2:时间轮
带着这个问题我们看看如果用我们的时间轮怎么去处理这个问题。先看一张图。这就像我们平时看到的钟表一样,在时间轮中有时间槽和时钟轮的概念,时间槽就是我们看到的每个槽位,时钟轮就是整个轮盘,也就是一个周期。
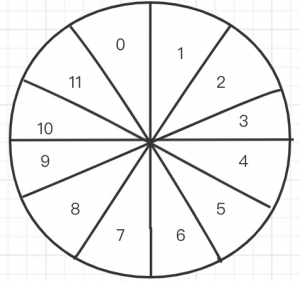
我们就按照上图事例,将每个任务放到对应的时间槽位上,如:设我们当前时间是0S,有一下3个不同超时时间的请求:2S、4S、10S,那么我们将不同定时任务放到不同的槽位上就得到了如下图的一个结果
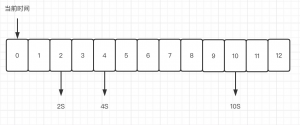
我们可以看到不同超时时间的请求被挂在了不同的时间槽上,根据我们的时间走动,我们会找到不同的超时请求接下来我们按照按照这个思路去走一下看看是怎样的一个情况:
当前时间:进入三个请求,分别是2S、4S、10S,分别放到了2、4、10时间槽上
1S:无请求,无需处理
2S:有一个超时的请求,将该请求从列表中清理掉(无需关注其他请求,节省了一次处理其他请求的时间)
4S: 有一个超时请求,将该请求从列表中清理
7S:假设这里有进来一个12S后超时的请求那么我们应该挂在哪呢? 从7往后数12个时间槽是在6那个槽位,我们继续往下走
10S:这里有一个请求,那么我们清理掉
当我们走到12的时候第13秒我们就像时钟一样又回到了0。依次反复。当我们再到6的时候会遇到我们那个12S后超时的那个请求
这里注意【遇到】而不是【找到】,我们只管大胆的往前一步一步的走,当该时间槽上有请求的时候我们处理一下该时间槽上的请求即可,无需刻意去找。(你我的相遇都是上天注定,无法逃脱)
有思想的人会想到如果有多个请求被划分到了同一个时间槽上怎么办呢?那就挂在原来那个请求后面呀,再多呢?那就继续挂呀,其实这里用链表或者红黑树都可以,看你个人的一个选择,但是需要注意的是,这里我们要做一个处理,排序,要保证每个最快到达超时时间的请求放在最上面,这样也是为了将来能节省下来很多的无效遍历。
总结
截止到这里我们再回过头去看看我们的第一个方案,做个比较:总共四个请求
方案一:从0S开始遍历,总共遍历了
前三秒:3 * 3 = 9
4~5: 2 * 2 = 4
6~8: 3 * 1 = 3
9~11:3 * 2 = 6
12~20:9 * 1 = 9
总共是:31次
方案二:从0S开始,在没有请求的时间槽上没有遍历
第2秒一次、第4秒一次、第10秒一次、第20秒一次
总共4次